

¿Lavado de derechos de autor? ¿Qué es eso?

El número de demandas contra empresas de inteligencia artificial ha aumentado considerablemente en los últimos meses, especialmente contra aquellas empresas que desarrollan modelos generativos. El centro de estas batallas legales es la infracción de derechos de autor (copyright) y el uso no autorizado de contenido protegido para entrenar modelos de IA. Han surgido casos emblemáticos como The New York Times contra OpenAI, Universal Music Group contra Anthropic y UMG Recordings contra Suno por el uso de música.
El problema radica en cómo se aplica la ley de derechos de autor al uso de obras existentes para entrenar inteligencia artificial. Tradicionalmente, los derechos de autor garantizan que los creadores tengan control sobre el uso y distribución de su trabajo. Sin embargo, el auge de la IA ha complicado este panorama, planteando la pregunta de si el uso de material protegido por parte de la IA generativa puede considerarse "uso justo".
El "uso justo" es un principio legal que permite el uso limitado de material protegido sin permiso. Uno de sus aspectos clave es si la nueva obra es "transformadora", es decir, si crea algo suficientemente distinto del original. Los defensores de los modelos generativos argumentan que estos cumplen con este criterio al generar resultados completamente nuevos a partir de obras protegidas.
No obstante, los límites entre lo que se considera uso transformador y plagio son difusos y sujetos a interpretación, lo que crea incertidumbre tanto para creadores como para empresas de IA. La proximidad de la obra generada al original también influye: cuanto más similar sea, menos probable es que se considere transformadora.
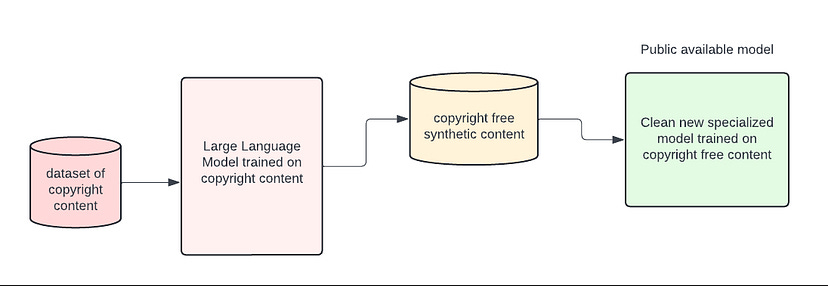
Para mitigar estos riesgos, algunos desarrolladores están explorando técnicas como introducir un nivel de disimilitud o "lejanía" respecto a la obra original, dificultando rastrear la conexión con la fuente protegida. Esto conduce al concepto conocido como "lavado de derechos de autor". El proceso implica entrenar un modelo de IA con contenido protegido y luego usarlo para generar datos sintéticos, que a su vez se utilizan para entrenar un segundo modelo considerado libre de preocupaciones legales.
Como explica Ed Newton-Rex:
"Los modelos serán reentrenados únicamente en datos sintéticos, intentando limitar los riesgos de derechos de autor y la necesidad de licenciar datos".
Este método crea una brecha entre el contenido original y el resultado final, haciendo casi imposible rastrear cualquier vínculo con la fuente. Aunque todavía existen desafíos, como el "colapso del modelo" donde la IA puede perder la riqueza y diversidad del contenido original, avances como la destilación de conocimiento están ayudando a superar estos obstáculos.
El cambio hacia el uso de datos sintéticos de alta calidad se está convirtiendo en una práctica común en la industria de la IA. Las empresas son conscientes de los riesgos legales y están trabajando en soluciones para evitar litigios futuros.
Fuente: https://medium.com/the-generator/copyright-laundering-a-new-ai-legal-strategy-c9b0bdcbf773